
Build a Secure Base in Rust (2026): A Practical, Auditable Foundation
how to build a secure base in rust usually comes down to one thing: setting up a foundation you can keep secure six months from now, not just passing a quick security review today. Rust removes whole classes of memory bugs, but it does not automatically give you safe dependencies, safe defaults, or safe deployments.
If you’re building an API, CLI, agent, or internal service for a US-based team in 2026, you’re probably juggling speed, compliance pressure, and a messy reality of third‑party crates. The “secure base” is where you decide what’s allowed, what gets blocked, and what gets audited, before features start piling up.
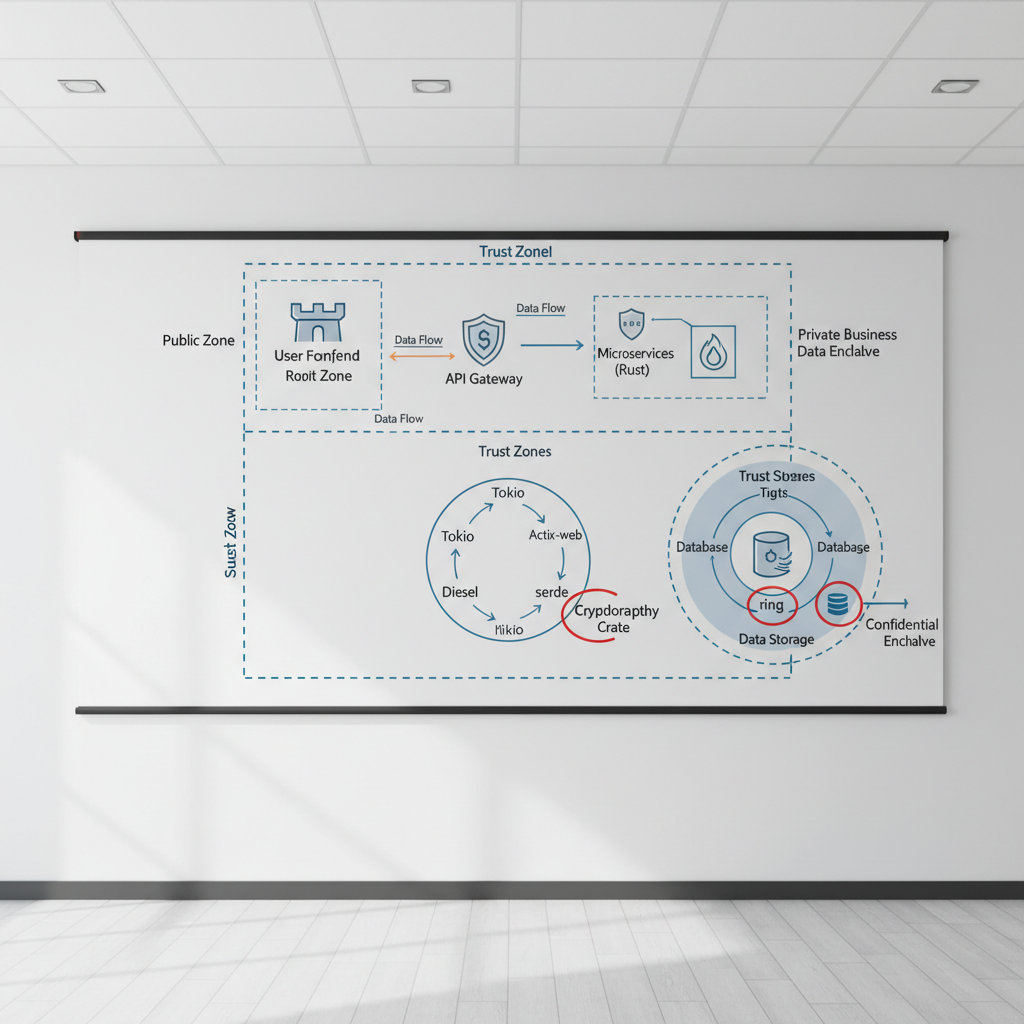
This guide focuses on choices that hold up under real engineering constraints: cargo settings, crate selection, CI gates, secrets handling, logging, and deployment hardening. You’ll also get a quick self-check, a lightweight table for “what to do when,” and a “when to call in help” section, because some risk calls deserve a second set of eyes.
What “secure base” means in Rust (and what it doesn’t)
A secure base is the minimum set of practices that makes your Rust project hard to break and easy to audit. Think guardrails, not a fortress. The point is to reduce risk from the most common failure modes: supply chain issues, unsafe code creep, misconfiguration, and missing runtime controls.
It does not mean you can skip security reviews because “Rust is safe.” Rust helps with memory safety, but many incidents come from logic flaws, auth mistakes, SSRF, dependency compromise, and leaked secrets, none of which Rust magically prevents.
- Rust helps: memory corruption, data races (in safe code), many lifetime bugs.
- Rust doesn’t solve: insecure defaults, weak auth, unsafe FFI boundaries, dependency trust, cloud misconfig.
Start with a threat model that’s small enough to finish
Before code structure, decide what you’re defending and who you’re defending against. Keep it simple: one page, updated occasionally. Many teams overthink this and end up doing nothing. A “good enough” model beats a perfect one you never maintain.
According to NIST (National Institute of Standards and Technology), threat modeling and secure development practices are core parts of building trustworthy systems, especially when you rely on third-party components.
A minimal template (works for most Rust services)
- Assets: user data, API tokens, internal credentials, build artifacts, logs.
- Entry points: HTTP endpoints, CLI args, message queues, files, environment variables.
- Trust boundaries: internet to API, service-to-service, host to container, app to database.
- Top risks: auth bypass, injection into downstream systems, SSRF, dependency compromise, secret leakage.
Write down the top 3 “nightmare outcomes” (data exposure, privilege escalation, remote code execution), then map which components could cause them. This will influence crate choices and what you lock down in CI.
Dependency and supply chain security: the real Rust foot-gun
For many modern Rust projects, the attack surface is less about your code and more about what you pull in. If you’re asking how to build a secure base in rust, dependency policy is where you get the biggest payoff early.

Practical defaults that reduce supply-chain surprises
- Pin Rust toolchain with
rust-toolchain.tomlso builds are reproducible across laptops and CI. - Lock dependencies with
Cargo.lock(even for libraries, if your org policy allows) and review diffs like code. - Run audits in CI:
cargo-auditfor known vulnerabilities, and treat findings as a triage queue, not noise. - Track licenses: use
cargo-denyto block disallowed licenses and flag duplicated versions. - Control “who can add crates”: require review for any new dependency, not just code changes.
According to the OpenSSF (Open Source Security Foundation), supply chain risk is a major driver of modern incidents, and automated checks plus strong review practices are common baseline recommendations.
Choosing crates with a security bias (quick heuristics)
- Prefer boring crates: well-known, actively maintained, with clear release notes and issues triage.
- Minimize transitive deps: fewer crates usually means fewer places for surprise behavior.
- Watch for “unsafe” surface: some crates legitimately use
unsafe, but you should know where and why. - Avoid “one-function crates” unless you trust the maintainer and the code is tiny and auditable.
Project structure and “safe-by-default” coding standards
A secure base is easier when your codebase makes risky behavior hard to introduce. You want conventions that nudge every engineer toward safer patterns without constant policing.
Baseline Rust settings worth enforcing
- Deny warnings in CI (not necessarily locally) to keep quality from drifting.
- Clippy as a gate: run
cargo clippy -- -D warningson pull requests. - Rustfmt consistency: formatting is not security, but it removes review friction.
- Explicit error handling: consistent use of
thiserroror similar, and no silent “unwrap” in production paths.
Control unsafe code instead of pretending it won’t happen
FFI, performance tricks, and low-level libraries can bring in unsafe. Your job is to make it visible and reviewable.
- Policy: allow
unsafeonly in specific modules, with clear comments on invariants. - Review rule: require senior review for any PR that adds or modifies
unsafe. - Testing focus: add property tests or fuzzing around unsafe boundaries, not just unit tests.
According to Rust Project documentation, unsafe Rust is a tool that shifts responsibility from the compiler to the programmer, which is exactly why it needs tighter process controls.
Security checks you can actually keep running (CI/CD baseline)
Most teams don’t fail at security because they ignore it, they fail because the process is too heavy and eventually gets skipped. Aim for checks that run fast and produce actionable output.
| Control | Tooling example | What it catches | How strict to be |
|---|---|---|---|
| Known vuln scan | cargo-audit | Advisories on crates | Block on high severity, triage the rest |
| License/deps policy | cargo-deny | License violations, duplicates | Block on disallowed licenses |
| Linting | clippy | Risky patterns, correctness issues | Block on warnings in CI |
| Fuzzing (optional baseline) | cargo-fuzz | Parser/edge-case crashes | Run nightly or on hot paths |
| Secret scanning | git hooks / CI scanners | Accidental key commits | Block on confirmed secrets |
- Key point: fail builds for issues that are unambiguous (known critical vulns, committed secrets), warn for the rest until the team builds the habit.
- Keep artifacts traceable: store build provenance and checksums if your org has compliance needs.
Runtime hardening: configs, secrets, logging, and network posture
Even a perfectly written Rust binary can be risky if it runs with broad permissions and loose network access. Runtime hardening is where “secure base” becomes real for production.
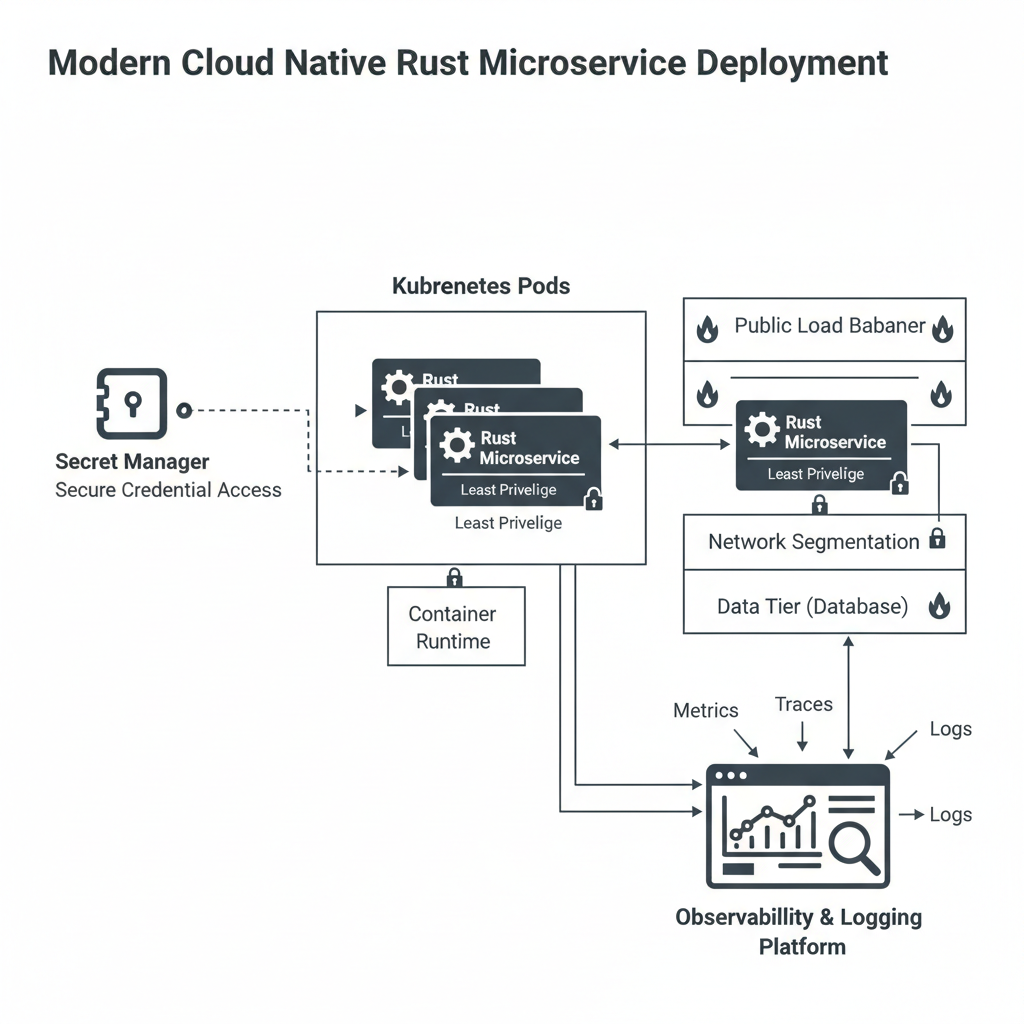
Secrets: treat them as toxic waste
- Prefer a secret manager (cloud-native or dedicated) over environment variables in long-lived environments, when possible.
- Never log secrets: redact sensitive fields in structured logs, and validate this with tests.
- Rotate: design for rotation early, because retrofitting rotation tends to hurt.
Least privilege defaults
- Drop root in containers, restrict filesystem access, and make writable paths explicit.
- Limit outbound traffic when your platform supports it, SSRF becomes harder when egress is constrained.
- Time out everything: HTTP client timeouts, database timeouts, and request body limits.
Logging and observability that helps security (not harms it)
- Structured logging (JSON) with request IDs, but avoid dumping whole payloads by default.
- Audit events: log auth decisions, privilege changes, and admin actions in a separate stream if possible.
- Crash behavior: ensure panics don’t leak sensitive context; decide when to restart vs fail closed.
Self-check: are you actually building a secure base?
If you want a quick gut check, use this list. If you can’t answer a question, that’s usually the work item.
- Dependencies: Can we explain why each major crate exists, and do we block unknown additions?
- CI gates: Do we run audits and lints on every PR, or only “sometimes”?
- Unsafe boundaries: Do we know where unsafe code lives, and who reviews it?
- Secrets: Could a developer accidentally print tokens in logs and not notice?
- Runtime limits: Do we have timeouts, size limits, and egress controls?
- Incident readiness: If a crate is compromised, can we identify affected builds and rotate credentials quickly?
Common mistakes that look “secure” but aren’t
These show up a lot in real reviews, especially when teams lean on Rust’s reputation and stop there.
- Overusing unwrap/expect in production request paths, then treating panics as “just crashes.”
- Ignoring transitive dependencies, even though they’re the majority of what you ship.
- Shipping with debug assumptions like verbose logs, open admin endpoints, or permissive CORS.
- Depending on TLS “somewhere” without validating certificate settings, timeouts, and hostname checks where the client runs.
- Skipping fuzzing for parsers and file formats, even when that code touches untrusted input.
When to bring in professional help (and what to ask for)
If your Rust system handles regulated data, money movement, healthcare information, or you’re shipping an agent that runs on customer machines, it’s usually smart to get a security review. The right time is before “launch week,” when fixes are still affordable.
- High-risk triggers: custom crypto, complex auth, multi-tenant data isolation, FFI-heavy code, or novel sandboxing.
- What to request: threat model review, dependency risk review, and a targeted pentest on auth + critical endpoints.
- Keep scope tight: ask reviewers to focus on the top 3 nightmare outcomes you listed earlier.
According to CISA (Cybersecurity and Infrastructure Security Agency), reducing exposure and building secure-by-design practices are important, and external validation can be part of a mature approach, especially for critical systems.
Practical “secure base” rollout plan (2 weeks to 2 months)
People ask how to build a secure base in rust as if it’s one switch. It’s more like a staged rollout where the team keeps shipping while guardrails tighten.
- Week 1-2: toolchain pinning, clippy gate, rustfmt, cargo-audit in CI, dependency review rule.
- Weeks 3-4: cargo-deny policy, secrets scanning, structured logging with redaction, timeouts and request limits.
- Month 2: fuzzing for parsers, unsafe code policy enforcement, deployment hardening and egress constraints.
Key takeaways: Rust buys you a safer starting point, but your secure base comes from disciplined dependencies, visible unsafe boundaries, CI gates that stay on, and runtime controls that assume mistakes will happen.
If you pick just two actions this week, make them these: add dependency auditing to CI, and enforce a policy around unsafe code and secrets handling. Everything else gets easier once those two are real.
FAQ
- Does Rust guarantee security by default?
Not really. Rust reduces memory-safety bugs in safe code, but security incidents often come from auth logic, insecure configs, and dependency compromise. - Is using fewer crates always more secure?
Often, but not always. Fewer dependencies can reduce attack surface, yet replacing a mature crate with a homegrown version can introduce new bugs, so weigh maintenance reality. - What is the minimum CI setup for a secure Rust baseline?
At minimum: pinned toolchain, tests, clippy gate, and a vulnerability scan like cargo-audit. Add license/dependency policy as soon as your org requires it. - How should we handle unsafe Rust in a production service?
Don’t ban it blindly. Track where it exists, document invariants, require stronger review, and add targeted testing around those boundaries. - What’s a reasonable approach to secrets in Rust apps?
Use a secret manager when feasible, keep secrets out of logs, and design for rotation. Environment variables can work in some setups, but they’re easy to mishandle at scale. - Should we fuzz test Rust code?
For parsers, file formats, and anything processing untrusted input, fuzzing is usually worth it. If resources are tight, run it nightly on the highest-risk modules. - How do we know if a dependency is “trusted enough”?
Look for maintenance activity, issue responsiveness, clear ownership, and understandable code surface. Also consider whether you can vendor or pin versions and review changes.
If you’re trying to standardize this across multiple repos, or you want a more hands-off path, a small internal “Rust secure base” template repo with CI checks, dependency policy, and runtime defaults can save a lot of repeated debate while keeping security decisions consistent.